Sample Data Pipelines
Below are sample flowcharts illustrating some of the data pipelines that I have designed, deployed, and worked on
ETL pipline: Azure Cloud Services
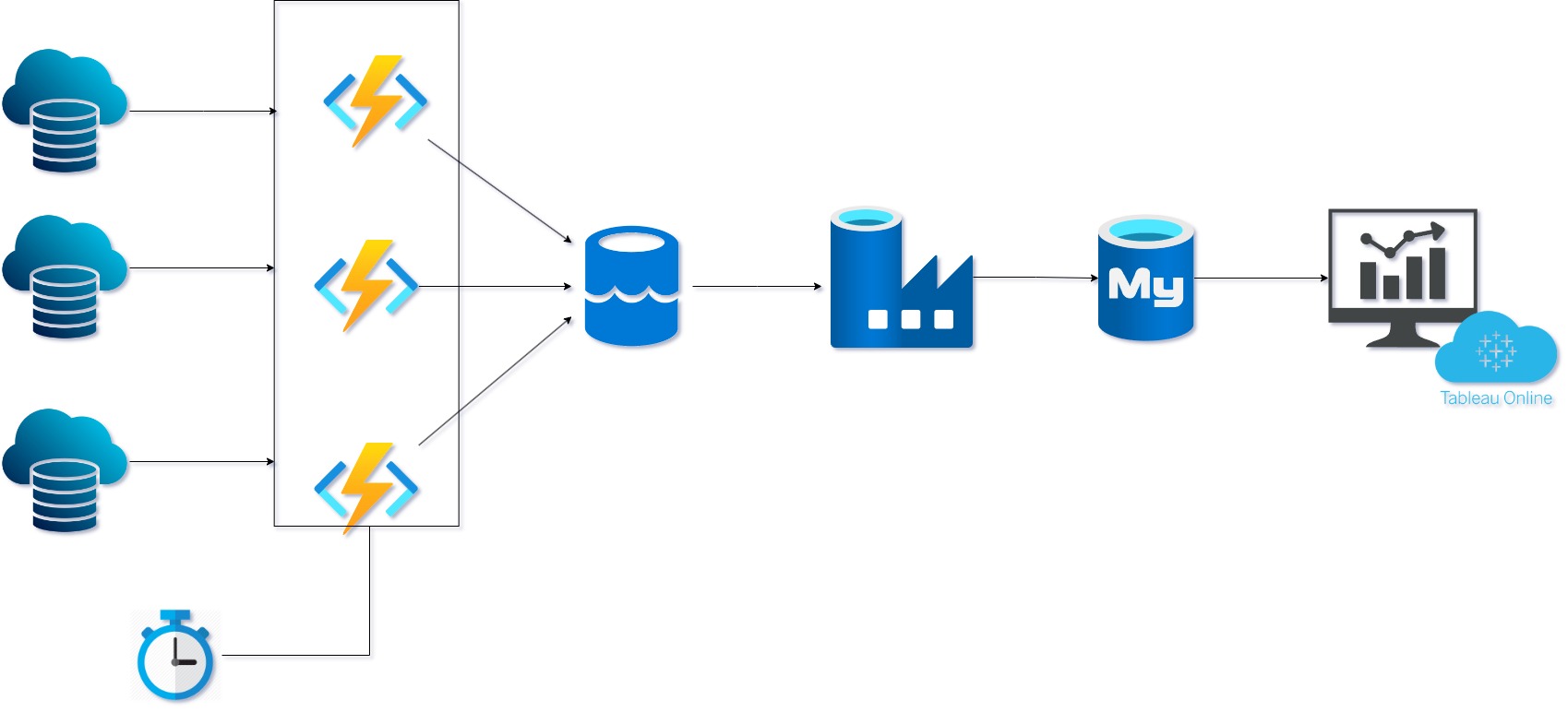
- Data ingestion through Azure Functions from multiple sources
- Data storage in Azure Data Lake
- Data transformation using Azure Data Factory
- Data loading into Azure SQL Database
- Interactive data visualization with Tableau Server
ETL BigData Pipeline: AWS Cloud Services
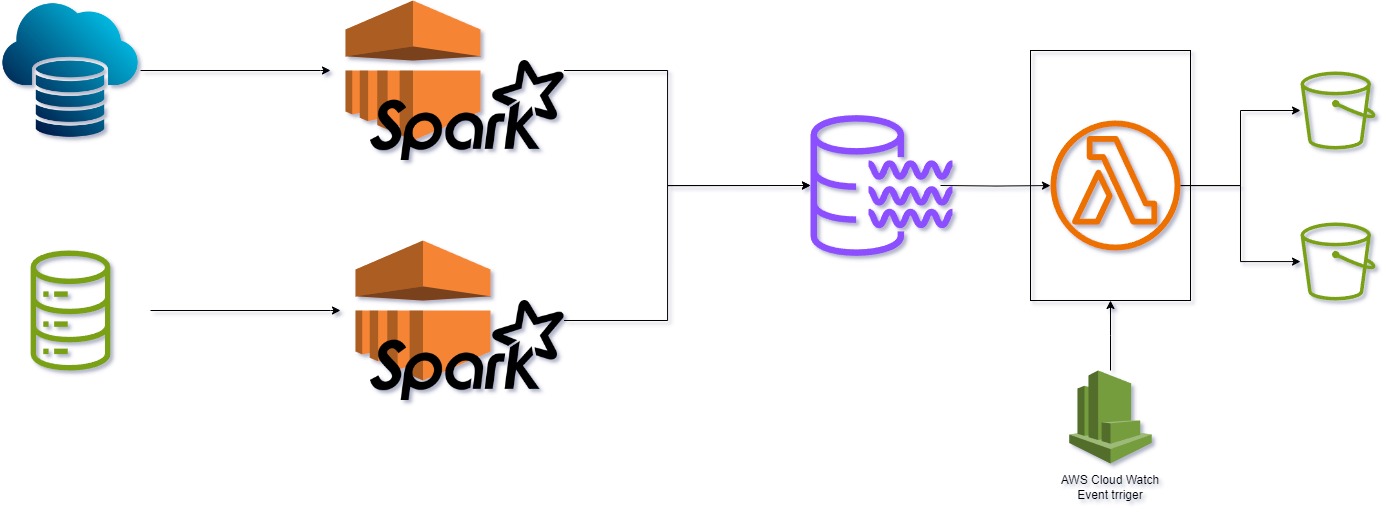
- Ingest data from both cloud resources and internal systems
- Perform data joining and processing using Amazon EMR with PySpark
- Store processed data in a centralized data lake
- Utilize AWS Lambda functions, triggered by CloudWatch events, for automation
- Load the processed data into an S3 bucket for business analytics and use
ETL BigData Pipeline: Airflow hybrid Cloud Services
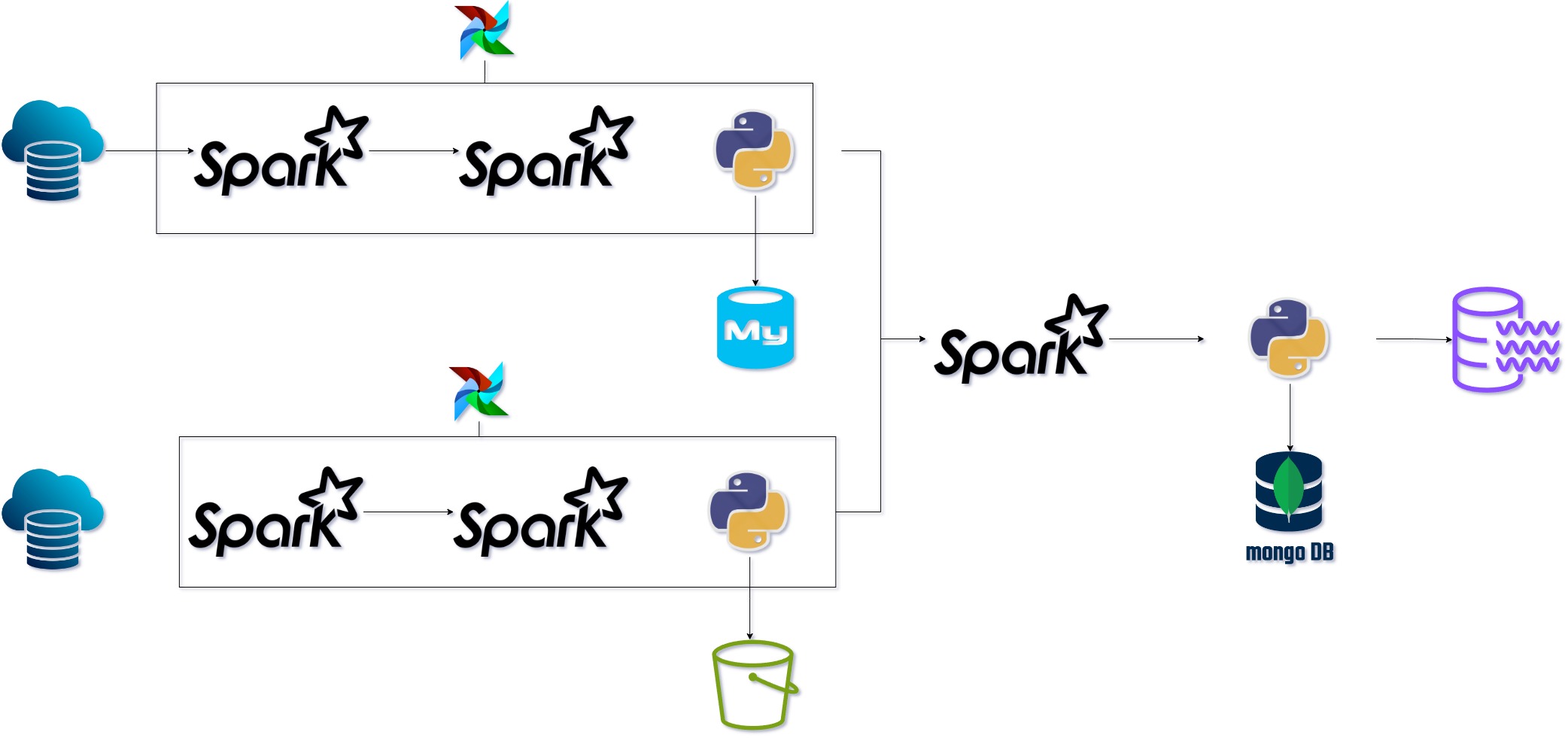
- Ingest data from various sources using PySpark SQL
- Extract internal information to S3 and MySQL server
- Join data using PySpark
- Extract additional internal information to MongoDB
- Load the processed data into an internal data lake
BigData Ingestion ETL: parallel processing, Docker-K8
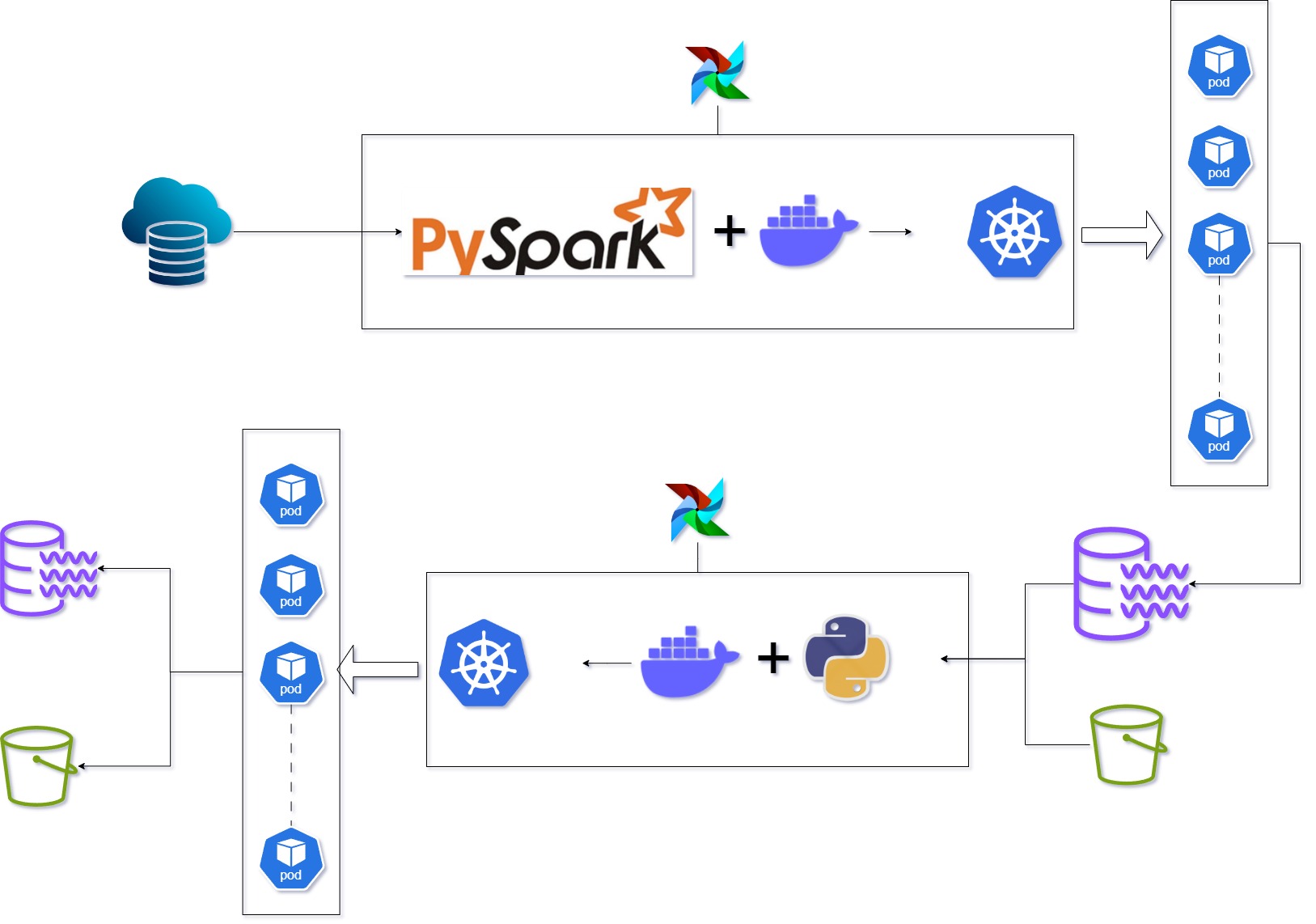
- Ingest data using a Docker image deployed within a Kubernetes cluster, utilizing parallel processing scheduled with Apache Airflow
- Execute transformation processes with Docker and Kubernetes
- Ingest data from S3
- Load the processed results into an internal data lake
- Backup the results to S3
Back to Home
View Resume